
Aprendizaje de Máquina

¿Qué es Machine Learning?⌗
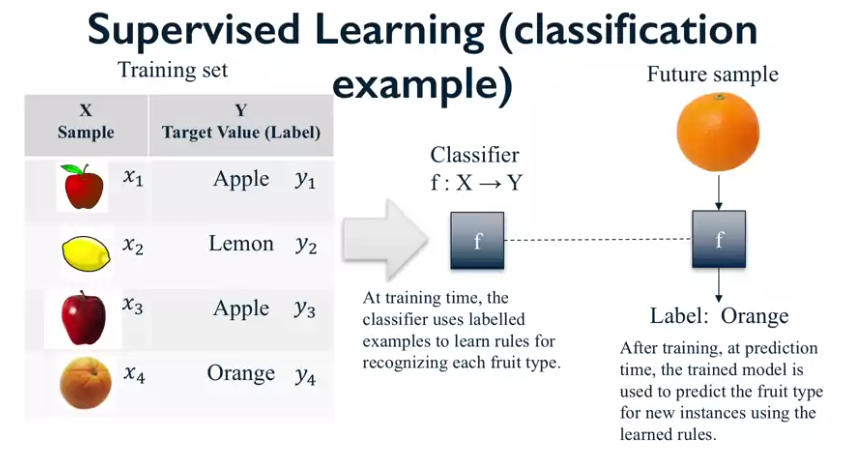
Los algoritmos de machine learning son capaces de generalizar a partir de ejemplos de una tarea:
- Ejemplo: un algoritmo de clasificación es capaz de "ver" imágenes etiquetadas en un set de datos de entrenamiento y aprender cómo aplicar estas etiquetas a nuevas imágenes jamás vistas anteriormente.
No todos los problemas se pueden resolver con la forma clásica de programación⌗
Problema clásico: ¿Cómo obtengo datos de una fuente de datos y los presento en una interfaz de usuario?
Problema nuevo: Convertir voz humana a texto
Debido a la gran complejidad de estos nuevos problemas, una serie de instrucciones (programa clásico) no basta para resolverlos de forma efectiva.
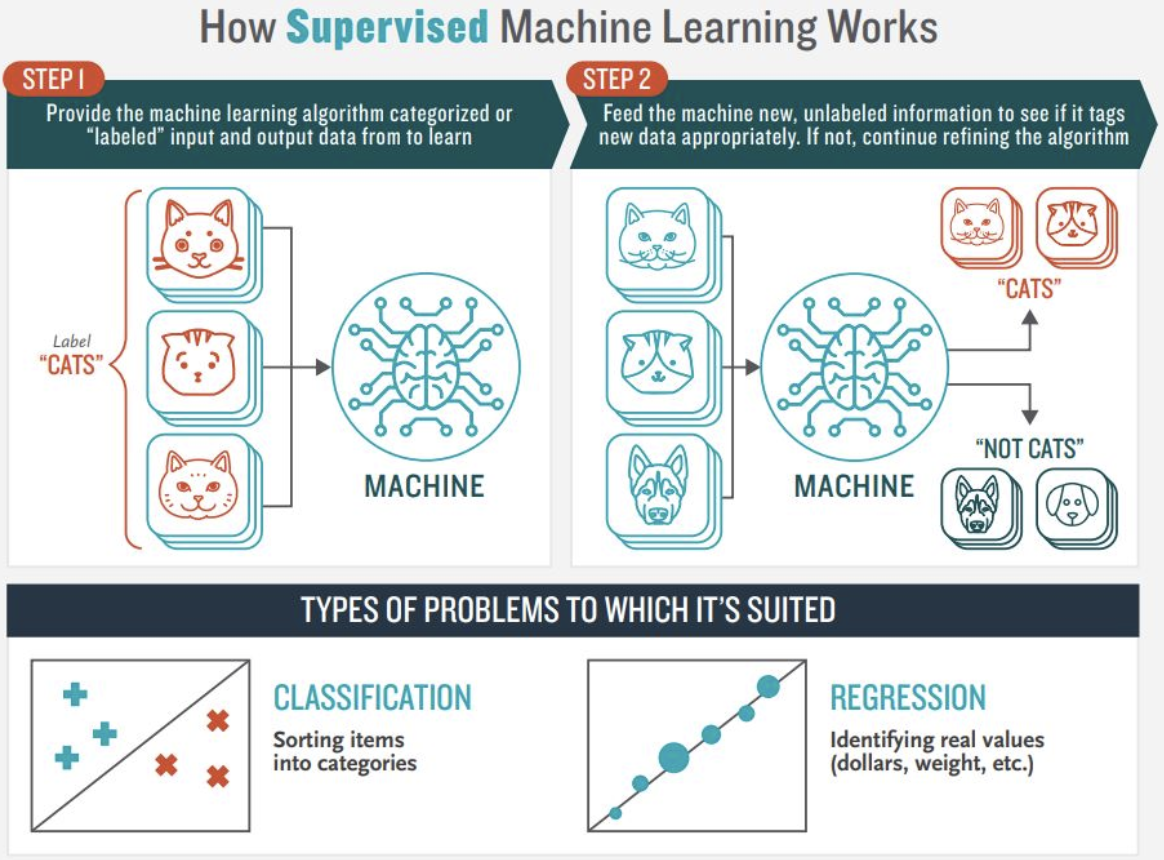
Los modelos de Machine Learning son capaces de aprender mediante ejemplos⌗
- Los algoritmos aprenden reglas a partir de ejemplos etiquetados
- Un set de ejemplos etiquetados utilizados para el aprendizaje es llamado training data (datos de entrenamiento)
- Las reglas aprendidas mediante los ejemplos deben poder generalizarse para reconocer correctamente o predecir nuevos ejemplos que no se incluyeron en el set de datos de entrenamiento.
El Machine Learning nos ofrece la tecnología que nos permite aprender reglas de forma eficiente a partir de ejemplos etiquetados (training data). Esta, resulta en una forma más precisa y flexible que tener que programar "a mano" una serie de instrucciones.
Problema básico de machine learning⌗
Uno de los objetivos principales del Machine Learning es explorar cómo los computadores pueden programarse a sí mismos para realizar una tarea, mejorando su rendimiento automáticamente a medida ganan experiencia.
Esta experiencia puede tomar forma en datos, en diferentes formatos o situaciones, como:
- Ejemplos etiquetados: clasificar spam de correos electrónicos.
- Feedback de usuarios: clicks de un usuario en una página web.
- Entorno inmediato: vehículos con piloto automático.

Para resolver este tipo de problemas, el machine learning se apoya en:
-
Métodos estadísticos que buscan
- Inferir conclusiones a partir de los datos.
- Estimar la certeza de las predicciones.
-
Ciencias de la computación
- Arquitecturas computacionales a gran escala (Big data).
- Algoritmos capaces de capturar, manipular, indexar, combinar, obtener y realizar predicciones en base a datos.
-
Economía, biología, psicología
- ¿Cómo puede un individuo o sistema mejorar eficientemente su rendimiento en un entorno determinado?
- ¿Qué es el aprendizaje? ¿Cómo puede optimizarse?
Aplicando Machine Learning⌗
Tipos de Aprendizaje de Máquina
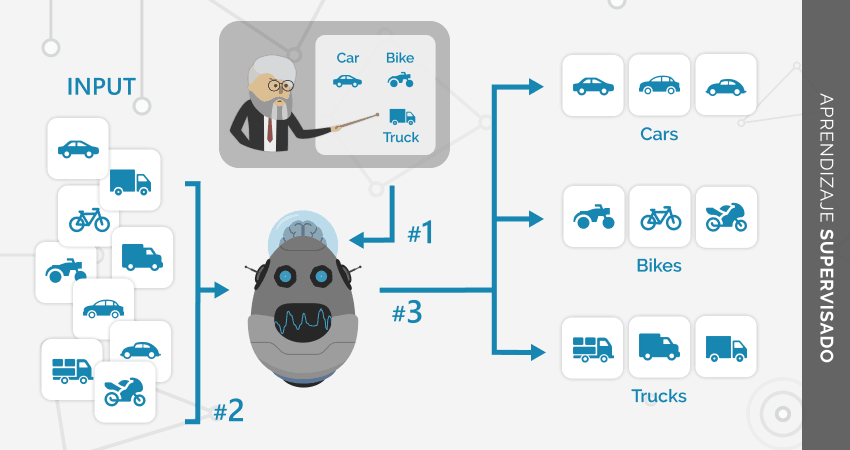
- Supervisado: aprender a predecir los valores ideales a
partir de datos etiquetados
- Clasificación: los valores ideales son clases discretas (un número de posibilidades finitas - ej: spam/no spam, masculino/femenino, camión/auto/motocicleta, limón/naranja/manzana/mandarina)
- Regresión: los los valores ideales son valores continuos (ej: kilos, temperatura, tiempo en segundos)
¿Quiénes clasifican las imágenes? ej: Amazon Mechanical Turk
- No Supervisado: encontrar estructuras en datos no
etiquetados
- Clustering: encontrar grupos de instancias similares en los datos
- Outlier detection (datos atípicos): detección de patrones inusuales
¿Cómo abordo un problema de Machine Learning?⌗
Flujo de trabajo básico:
1) Representación (Feature Representation): consiste en representar el problema de una forma en la que un computador pueda entenderlo. En esta fase se analiza el problema y selecciono:
-
Atributos/Características/Propiedades que describen al/los objeto(s):
ej: pixeles de una imagen -
Tipo de algoritmo a utilizar: seleccionar el mejor modelo de machine learning
ej: clasificador de k-vecinos más cercanos
2) Evaluación (Evaluation): permite chequear y comparar la eficiencia de los distintos modelos, para así saber (a ciencia cierta) qué modelos tienen buenos resultados y cuáles no. En esta fase selecciono:
- ¿Qué criterios distinguen a un buen modelo de uno malo?
ej: porcentaje de predicciones en un set de datos de prueba
3) Optimización (Optimization): en este paso buscamos por el modelo óptimo, que nos de los mejores resultados basándonos en la evaluación previa. En esta fase seleccionamos:
- La configuración/parámetros que den al modelo el mejor rendimiento.
ej: probar con una serie de valores como parámetros para un clasificador de k-vecinos más cercanos