
Sistemas distribuidos - Introducción

“El hecho de que estemos conectados a través del espacio-tiempo evidencia que la vida es un fenómeno unitario, sin importar el cómo se manifieste esta realidad.” Lynn Margulis
En sus comienzos los sistemas distribuidos no pasaban de ser una curiosidad académica y sólo se pensaba que quizás algún día llegarían a ser útiles, pero no hoy. Al pasar el tiempo y gracias al crecimiento exponencial de los sistemas de información en los últimos 20 años, estos han llegado a tener un rol fundamental en gran parte de los sistemas que hoy en día operan, sobretodo en los masivos. Si bien muchos de los desafíos y problemas ligados a los sistemas distribuidos fueron ya resueltos, todavía existen muchos otros que requieren atención de mentes curiosas.
En palabras simples un sistema distribuido es un grupo de computadoras que de forma cooperativa se comunican entre sí a través de una red, esto con el objetivo de completar una tarea.
Algunos ejemplos de sistemas distribuidos:
- Almacenamiento para páginas web de gran tamaño
- Realizar cómputos para tareas de Big Data
- Compartir archivos en redes P2P peer to peer / entre pares
Cabe destacar que muchas de las infraestructuras críticas en las cuales operan grandes sistemas informáticos están construidas sobre sistemas distribuidos.
Cuando se tiene un martillo todo parece un clavo
A pesar de que los sistemas distribuidos son utilizados en variados sistemas, esto no significa que todo deba construirse como un sistema distribuido. Si debemos resolver un problema, y éste puede ser resuelto por una sola computadora, hacerlo de esta forma será mucho más sencillo y se ahorrarán muchos recursos que en etapas tempranas pueden ser innecesarios.
Razones por las cuales construir un sistema distribuido⌗
Sin embargo, existen motivos por los cuales implementar un sistema distribuido tendría lógica y algunos de éstos son:
- Alto rendimiento: esto puede conseguirse a través de alguna forma de paralelismo, ya sea en cpu, ram o en disco.
- Tolerancia a fallos: si una tarea es distribuida en múltiples máquinas y una de ellas falla, ésta pueda ser reemplazada por otra.
- Lugar físico: los computadores están ubicadas físicamente/geográficamente en lugares distintos.
- Seguridad: se logra seguridad dividiendo a las máquinas en nodos para que así se encuentren aisladas .
¿Por qué los sistemas distribuidos resultan difíciles de implementar?⌗
La implementación de sistemas distribuidos representa un reto debido a las siguiente razones:
- Concurrencia: ya que los sistemas distribuidos utilizan la concurrencia, hereda todos sus problemas y/o desafíos.
- Fallos parciales: debido a que el sistema es divido en múltiples piezas operando al mismo tiempo en una red, encontraremos patrones de fallos muy específicos, donde algunas piezas del sistema fallan y otras siguen funcionando.
- Rendimiento: conseguir el rendimiento deseado requiere de un trabajo cuidadoso.
Infraestructura⌗

Uno de los usos más comunes de los sistemas distribuidos es en la forma de infraestructura, es decir, donde operan y funcionan las aplicaciones de software.
Las infraestucturas más frecuentes son:
- Almacenamiento
- Comunicación
- Computación
¿Cuál sería el objetivo final a la hora de construir un sistema distribuido?⌗
Descubrir abstracciones y simplificar la interface, de esta forma construir aplicaciones basadas en este tipo de sistemas resulta más fácil. Tener una interfaz que oculte la naturaleza distribuida del sistema hará que éste parezca uno tradicional/centralizado, tal como un sistema de archivos.
Ejemplos de implementación⌗
Algunas de las herramientas que necesitamos para construir sistemas distribuidos son:
- RPC Remote procedure calls/Llamadas de procesos remotos: su propósito es ocultar el hecho de que la comunicación se realiza mediante una red no confiable o inestable.
- Hilos: técnica de programación que permite la utilización de computadores con múltiples núcleos (cores). Los hilos son una forma de estructurar operaciones concurrentes, esto con el fin de simplificar la visualización de las operaciones.
- Control de la concurrencia: se asegura que las operaciones concurrentes generen resultados correctos, mientras los obtiene de la forma más rápida posible.
Abstracciones / Tópicos recurrentes⌗
Rendimiento: usualmente, uno de los de los objetivos principales al construir un sistema distribuido es alcanzar una velocidad escalable.
- Escalabilidad: el rendimiento escala a medida crece la red, es decir, a mayor cantidad de computadoras mayor será la capacidad cómputo o se verá una reducción del tiempo necesario para ellas. Esto es importante ya que los recursos necesarios para añadir una computadora hoy en día son mucho menores en comparación a contratar a un equipo de programadores que busquen la forma de reestructurar el software para aumentar el rendimiento.
Ejemplo simple de escalabilidad
Imaginemos que somos los administradores de una web que acaba de salir al mercado y su arquitectura vista desde un alto nivel se ve algo así:
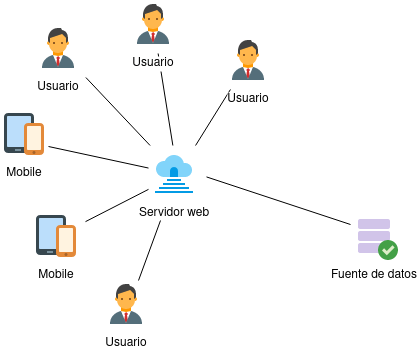
Cuando tenemos pocos usuarios tener esta arquitectura de computadoras individuales tiene sentido. Sin embargo, luego de un tiempo, la aplicación comienza a tener gran éxito y las métricas de los servicios e infraestructura demuestran que se está llegando a su límite.
Una de las soluciones a este problema sería buscar alternativas que optimicen las tareas llevadas a cabo por el software, pero no hay tiempo para eso y quizás tampoco los recursos. La opción lógica sería entonces añadir más servidores web y dividir la carga entre ellos, de esta forma obtenemos un aumento del rendimiento de forma paralela.
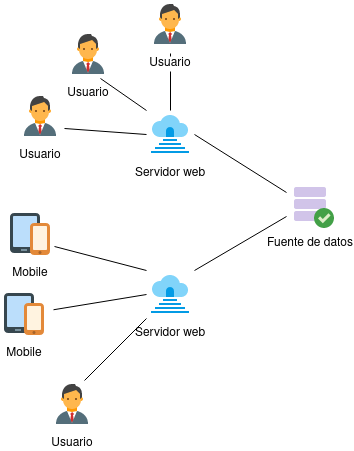
Desafortunadamente, si la demanda sigue creciendo habrá un punto en el cual añadir más servidores ya no ayudará al rendimiento y notaremos algún cuello de botella en el sistema. Luego de un análisis de las métricas notaremos que en realidad la solución anterior movió el cuello de botella hacia otra parte del sistema, probablemente hacia la fuente de datos. Ya en este punto nos veríamos obligados a realizar algún tipo de trabajo en el diseño en la arquitectura del sistema, debido a que sería muy poco probable que simplemente añadiendo otra máquina solucionemos el problema y tal tarea llevaría trabajo.
Tolerancia a fallos:⌗
El resolver problemas de gran escala con sistemas distribuidos hace que la tolerancia a fallos sea carente y los errores se hagan más recurrentes a medida crece la red. Es por ello que la habilidad de detectar errores y seguir funcionando a pesar de ellos debe ser parte del sistema, enmascarando al mismo tiempo ciertos tipos de errores a los usuarios de la interface. Esto, debido a que no es necesario que los usuarios se enteren de todos los errores que ocurren en la red si la funcionalidad no es afectada directamente.
¿Qué significa que el sistema el sistema sea tolerante a fallos?
La tolerencia a fallos puede ser definida de múltiples formas y puede adaptarse a diversos contextos, a pesar de ello, es posible encontrar ideas comunes que se asocian a un sistema tolerante a fallos, como:
- Disponibilidad: el sistema seguirá operativo frente a un set definido de fallos. Se desprende entonces que existirán escenarios en los cuales el sistema fallará y no podrá seguir operativo.
- Recuperación: el sistema es capaz de recuperarse sin pérdidas mayores y seguirá “computando” correctamente, con la esperanaza de que el error y/o su causa sean eventualmente solucionados.
- Ejemplos de herramientas:
- Non volatile storage (Dispositivos de almacenamiento no volátiles). Uno de los desafíos en este tipo de sistema es la optimización de escritura en el disco, de tal forma que se evite la necesidad de escribir y/o sobreescribir en él en cada operación.
- Replicación: la administración de copias de seguridad es una tema complejo debido a la sincronización de copias, donde preguntas como ¿qué pasa cuando una copia deja de estar sincronizada y ya no es considerada una réplica? afloran en el diseño de sistemas distribuidos.
- Ejemplos de herramientas:
Consistencia⌗
Comencemos con una definición formal: “La consistencia es el acuerdo al que llegan múltiples nodos de la red al computar ciertos valores”. Este “acuerdo” puede tomar muchas formas dentro de un sistema distribuido y a esto le llamamos modelos de consistencia. Los modelos de consistencia son entonces las reglas que siguen las operaciones/cómputos y cómo sus resultados son luego definidos o acordados.
Imaginemos un caso:
Debemos desarrollar un bingo online, permitiendo que en tiempo real cada jugador pueda señalar si es ganador de cada uno de los premios. A medida que se anuncia cada número al azar los jugadores irán tachando en paralelo el correspondiente en su cartola virtual. El problema aparece cuando consideramos los factores que podrían influir en el proceso, como una conexión a internet lenta o una inconsistencia en los datos. Sin reglas establecidas el programa podría declarar como ganador a un jugador que no necesariamente sea el primero en completar el bingo o múltiples participantes podrían coincidir al considerarse como ganadores.
En un sistema distribuido este tipo de problemas se hacen recurrentes, es por ello que los modelos de consistencia toman relevancia. Las reglas que definimos para considerar si un cómputo/resultado es correcto será entonces nuestro modelo de consistencia. Los modelos de consistencia fuertes poseen reglas más estrictas que su contraparte (débiles). En un modelo de consistencia fuerte, cualquier procesamiento de los datos debe ser bloqueado durante el periodo de actualización o replicación, esto con el fin de asegurar que otros procesos no modifiquen los mismos datos. Debido a lo anterior, los desarrolladores deben comprometer escabilidad y rendimiento en sus aplicaciones. Dar la capacidad de siempre poder ver el último dato escrito es entonces un requerimiento difícil de implementar, además de requerir mucha comunicación entre los nodos de la red. Es por ello que por regla general los modelos de consistencia débiles resultan más útiles para un abanico más amplio de problemas.
Para concluir resulta evidente la importancia que toman los sistemas distribuidos hoy en día en las infraestructuras de aplicaciones masivas y el internet en general. Entenderlas, aunque sea de forma superficial nos ayuda a añadir nuevos sets de herramientas a nuestro repertorio y ver cómo dar solución a un set definido de problemas. En siguientes publicaciones profundizaremos en algunas implementaciones que nos darán una mejor idea acerca de este tema, tocando tópicos como MapReduce, algoritmos de consenso, tolerancia a fallos, entre otros.